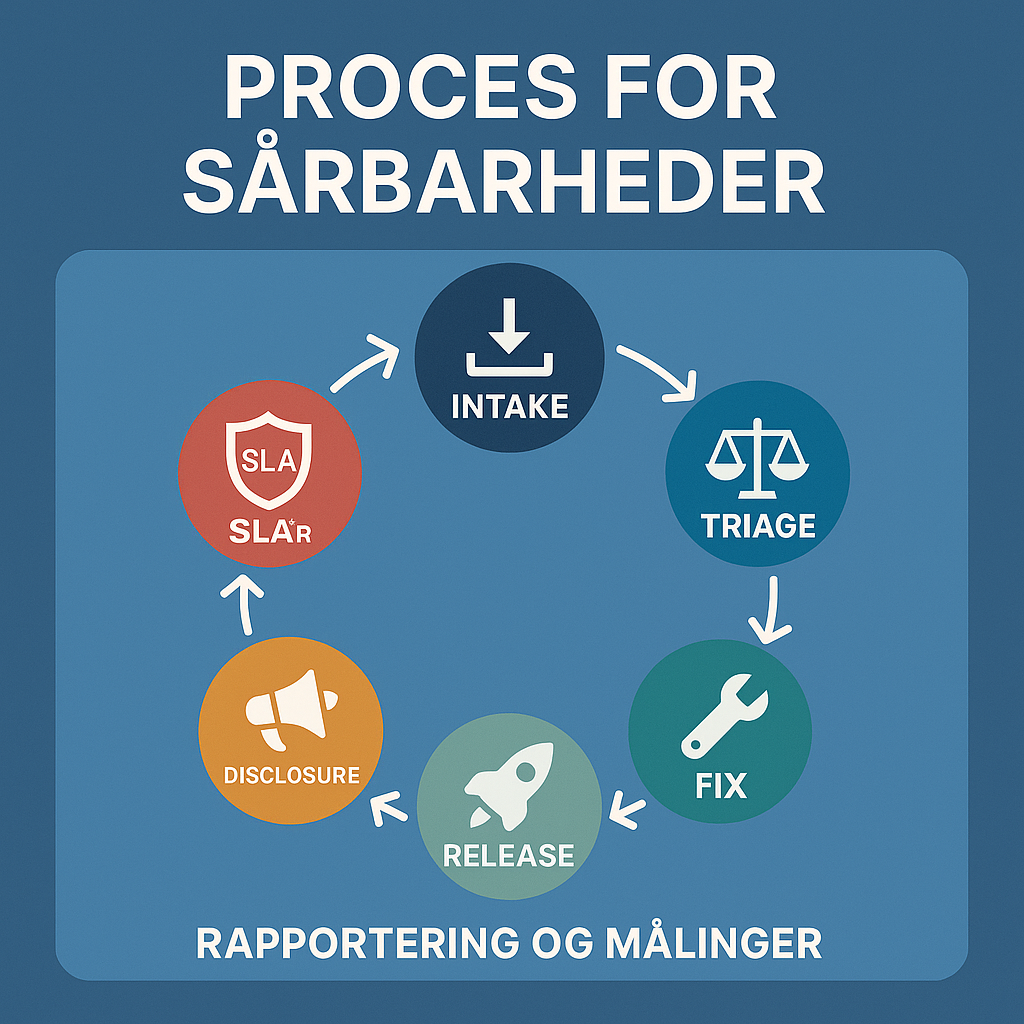
En moden proces for håndtering af sårbarheder gør forskellen mellem kontrolleret risiko og hektisk brandslukning. I denne artikel får du en praktisk, trin-for-trin gennemgang af intake, triage, fix, release og disclosure, plus hvordan du bygger SLA’er, rapportering og målinger, der faktisk styrer adfærd.
Du får konkrete arbejdsgange, typiske faldgruber og forslag til skabeloner, så du kan implementere en ensartet sårbarhedsproces på tværs af teams uden at drukne i administration. Undervejs bliver “hvad, hvorfor og hvordan” besvaret, så du kan gå direkte fra principper til drift.
Hvad er en sårbarhedsproces, og hvorfor betyder den noget?
En sårbarhedsproces er en aftalt kæde af aktiviteter, der sikrer, at fund af sikkerhedsfejl bliver modtaget, vurderet, udbedret, frigivet og eventuelt offentliggjort på en kontrolleret måde. Det betyder noget, fordi sårbarheder sjældent er farlige i sig selv; de bliver farlige, når de bliver ignoreret, misforstået eller håndteret uensartet.
En god proces reducerer “mean time to remediate”, skaber sporbarhed og gør det muligt at prioritere indsats efter reel risiko i stedet for støj fra scanninger. Mini-konklusion: Procesdisciplin er en sikkerhedskontrol, ikke et administrativt lag.
Intake: sådan modtager du fund uden at miste dem
Intake handler om at gøre det let og ensartet at indrapportere sårbarheder fra alle kilder: automatiske scans, penetrationstest, bug bounty, kunder, interne udviklere og drift. Målet er at sikre, at hvert fund får et unikt ID, ejerskab og minimumsinformation til at kunne vurderes.
Kilder, kanaler og minimumsfelter
Standardisér indgangen: et ticket-system, et dedikeret e-mail-alias, eller en formular i dit interne portal. Vigtigere end kanalen er kvaliteten af data. Kræv et minimum af felter, så triage ikke går i stå.
- Asset eller produkt (service, app, bibliotek, miljø)
- Fundets type (CWE, fejlklasse, misconfiguration)
- Reproducerbarhed (trin, payload, proof)
- Eksponeringsflade (internet, intern, partner)
- Konsekvens (data, drift, privilegier)
- Kilde og tidspunkt (scan, tester, kunde)
Duplikater og støj tidligt
Mange organisationer mister tid på dubletter. Lav en regel: samme root cause i samme komponent er ét fund, der samler observationer. Brug labels til “dupe”, “needs info” og “false positive”, så intake ikke bliver en sort boks.
Mini-konklusion: God intake er en støjfilter, der giver triage et klart udgangspunkt.
Triage: prioritering, risiko og ejerskab i praksis
Triage er beslutningslaget: Hvad er det? Hvor slemt er det? Hvem ejer det? Hvornår skal det fixes? Her går mange fejl, fordi man enten kun kigger på en CVSS-score eller kun på mavefornemmelse. Brug i stedet en enkel, reproducerbar model, der kombinerer teknisk alvor med kontekst.
Fra CVSS til kontekstbaseret prioritet
CVSS er nyttig som fælles sprog, men den siger ikke alt om din virkelighed. Tilføj kontekst: om systemet er internetvendt, om exploit findes, om der er kompenserende kontroller, og om data er følsomme. Et “Medium” i et kritisk kundesystem kan være mere presserende end et “High” i et lukket testmiljø.
En pragmatisk triage kan ende i fire prioriteringsniveauer: P1 kritisk, P2 høj, P3 normal, P4 lav. Bind derefter hvert niveau til en SLA og en standard-handling, så udvikling og drift ved, hvad der forventes.
RACI og beslutningsret
Uden klart ejerskab dør sager i køen. Definér en RACI: hvem er Responsible for fix, hvem er Accountable for risiko, hvem skal Consulted, og hvem skal Informed. Typisk er produktteamet ansvarligt, sikkerhed er rådgivende og kvalitetssikrer triage, mens ledelsen ejer accept af resterende risiko.
Mini-konklusion: Triage skal være konsekvent, ellers er SLA’er og målinger værdiløse.
Fix: udbedring, kompensation og teknisk gæld
Fix-fasen er mere end at “patch’e”. Den handler om at vælge den rigtige udbedring: opgradering, konfigurationsændring, kodeændring, eller en midlertidig kompensation, hvis en reel løsning kræver større omlægning. Et centralt spørgsmål er “hvordan undgår vi, at det sker igen?”.
Start med root cause: er det et bibliotek, en fejl i inputvalidering, manglende auth, eller en IaC-konfiguration? For softwareteams bør fix kobles til tests og coding guidelines; for drift bør fix kobles til baseline, hardening og ændringsstyring.
- Bekræft fundet og reproducer i kontrolleret miljø
- Find root cause og berørte versioner
- Vælg løsning: patch, config, kode eller kompensation
- Tilføj test eller kontrol, så fejlen fanges fremover
- Dokumentér ændringen og opdater trusselsmodellen
Hvad koster det? Omkostningen styres af to ting: hvor tidligt du fanger det, og hvor standardiseret din platform er. En sårbarhed i et centralt bibliotek med automatiseret dependency-opdatering kan være minutter; en sårbarhed i monolit uden tests kan være uger. Mini-konklusion: Invester i forebyggelse som CI-sikkerhed og dependency-hygiejne, så “fix” bliver en rutine.
Release: sikre ændringer uden at bremse leverancer
Release er stedet, hvor gode intentioner ofte kolliderer med drift. Hvis sikkerhedsfixes altid kræver særbehandling, vil teams enten undgå dem eller tage risikable genveje. Målet er at gøre sikkerhedsrettelser til en normal del af release-flowet.
Hotfix vs. normal release
Definér klare kriterier for hotfix: aktiv udnyttelse, interneteksponering, eller brud på compliance-krav. Ellers kør rettelsen i normal cadence. Vigtigst er, at du har en standard playbook: feature flags, rollback-plan, canary releases og monitorering af fejlrate.
Verifikation og sign-off
Verifikation bør være risikobaseret: for P1/P2 kræv bevis for afhjælpning (scan, retest, log-bevis) og en kort sikkerhedsgodkendelse. For P3/P4 kan automatiske checks være nok. Når du designer processer, er det nyttigt at se release som en del af vulnerability management, hvor kvaliteten i pipeline afgør hastigheden i praksis.
Mini-konklusion: Et godt release-flow gør det let at gøre det rigtige og svært at gøre det farlige.
Disclosure: koordinering, ansvar og timing
Disclosure handler om, hvornår og hvordan information om en sårbarhed deles med andre: kunder, partnere, open source-brugere eller offentligheden. Det er både en tillidsøvelse og en risikostyringsdisciplin. Typiske spørgsmål er: Skal vi offentliggøre? Hvornår? Og hvad skriver vi?
Brug coordinated disclosure som standard: giv berørte parter tid til at opdatere, før detaljer bliver bredt kendt. Sæt en tidsramme, f.eks. 30–90 dage afhængigt af risiko og økosystem. Hvis der er aktiv udnyttelse, kan du vælge hurtigere publicering sammen med midlertidige afværgeforanstaltninger.
- Forbered en advisory med påvirkede versioner og løsning
- Beskriv afbødning, hvis patch ikke er mulig med det samme
- Angiv CVE/CVSS hvis relevant, men forklar konteksten
- Koordinér med support, så de kan hjælpe kunder
- Log beslutninger om timing og undtagelser
Faldgrube: at skrive uklare advisories, der skaber panik eller misforståelser. Undgå det ved at være konkret, kort og handlingsorienteret, og ved at adskille “hvad vi ved” fra “hvad vi undersøger”. Mini-konklusion: God disclosure reducerer sekundær skade som support-byrde og rygter.
SLA’er: realistiske tider, undtagelser og risikaccept
SLA’er for sårbarheder er løfter om responstid og udbedringstid. De skaber forudsigelighed, men kun hvis de er realistiske og knyttet til prioritet. En klassisk fejl er at kopiere en standardtabel uden at have kapacitet, hvilket fører til konstant brud og “SLA-træthed”.
Definér to tider: time-to-ack (hvornår er fundet set og ejet) og time-to-remediate (hvornår er risikoen reduceret). “Remediate” kan i nogle tilfælde være en kompensation, hvis den dokumenteret reducerer risiko til et acceptabelt niveau.
Et eksempel på SLA’er kan være: P1 ack inden 24 timer og fix/mitigation inden 7 dage; P2 ack inden 3 dage og fix inden 30 dage; P3 ack inden 7 dage og fix inden 90 dage; P4 i backlog med planlagt vindue. Justér efter din branche og trusselsbillede, og vær eksplicit om undtagelser som tredjepartsafhængigheder.
Risikaccept bør være en formel beslutning med udløbsdato. Ingen accept uden ejer: den accountable part skal signere, og sikkerhed skal kunne følge op. Mini-konklusion: SLA’er virker kun, når undtagelser er styrede og tidsbegrænsede.
Rapportering og målinger: det der bliver målt, bliver håndteret
Rapportering skal hjælpe teams med at handle, ikke bare informere ledelsen. Skab dashboards, der kan brydes ned per produkt, team og miljø, og som viser både flow og risiko. Start småt og stabilt: få målinger, høj kvalitet.
KPI’er der styrer adfærd
Gode målinger afspejler processen. Fokusér på tid, volumen, kvalitet og rest-risiko. Undgå at belønne “lukket antal sager” alene, da det kan føre til overfladiske fixes eller aggressiv nedprioritering.
- MTTA og MTTR pr. prioritet
- Andel sager inden for SLA
- Aldersfordeling på åbne sager (aging buckets)
- Reopen-rate og recurrence (samme root cause)
- Dækning: hvilke assets scannes og hvor ofte
- Eksponering: internetvendte P1/P2 over tid
Rapportering til forskellige målgrupper
Til udviklere: konkrete backlogs, reproduktion, og komponentniveau. Til produktledelse: risiko og plan. Til direktion: trend og kritiske undtagelser. Brug samme datagrundlag, men forskellig framing. En hyppig faldgrube er at bygge rapporter, der kræver manuel Excel-indsats; automatisér udtræk fra tickets og scanninger, ellers stopper rapporteringen, når det bliver travlt.
Mini-konklusion: Målinger skal skabe læring, ikke skyld.
Typiske fejl og bedste praksis: sådan gør du processen robust
De mest almindelige fejl er forudsigelige: for mange værktøjer uden fælles flow, uklart ejerskab, og prioritering uden kontekst. Derudover ser man ofte, at teams “fixer” ved at undertrykke alerts, eller at sikkerhed bliver en flaskehals, fordi al triage centraliseres.
Bedste praksis er at designe for skalerbarhed: automatisér hvor du kan, standardisér hvor du bør, og bevar menneskelig vurdering dér, hvor kontekst er afgørende. Sørg for, at sårbarhedsprocessen er integreret i eksisterende udviklings- og driftsrytmer som sprintplanlægning, change management og incident response.
Konkret kan du styrke robustheden ved at: holde en ugentlig triage-session for P1/P2, bruge skabeloner til advisories, definere “definition of done” for sårbarheder, og løbende kalibrere prioriteringsmodellen med faktiske hændelser og penetrationstest-resultater. Små justeringer ofte slår store reformer sjældent.
Mini-konklusion: Robusthed kommer af gentagelse, klare regler og løbende forbedringer.



